[1] 1 2 3 4 5 6 7 8 9 10Correspondence analysis
Results
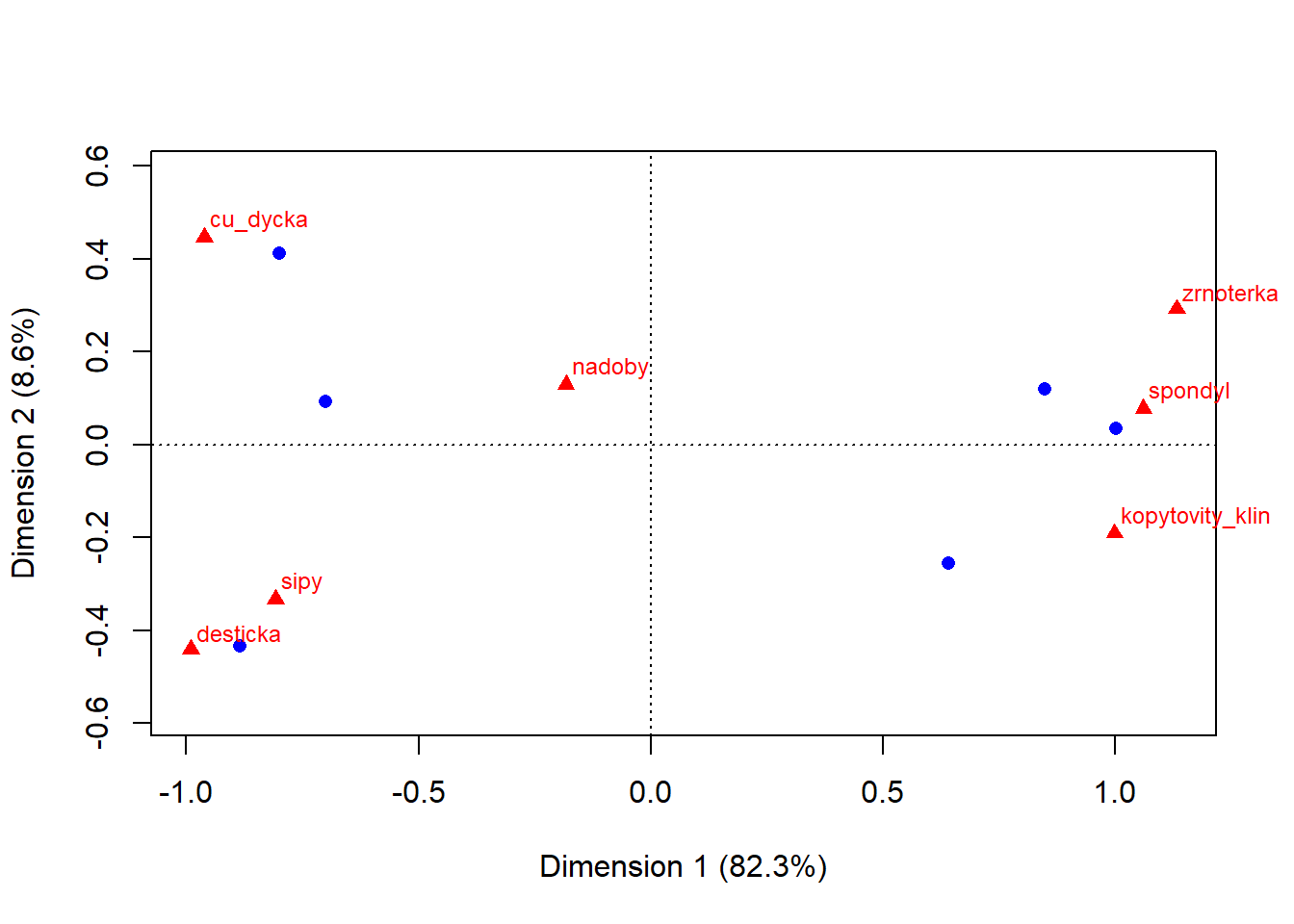
- notice we are running the analysis only with columns which represent number of artefacts (2nd to 8th)
- also notice there are two types of points in the plot:
- blue circles represent row values, which are in this case graves
- red triangles represent column values - numbers of specific artefacts
Interpretation
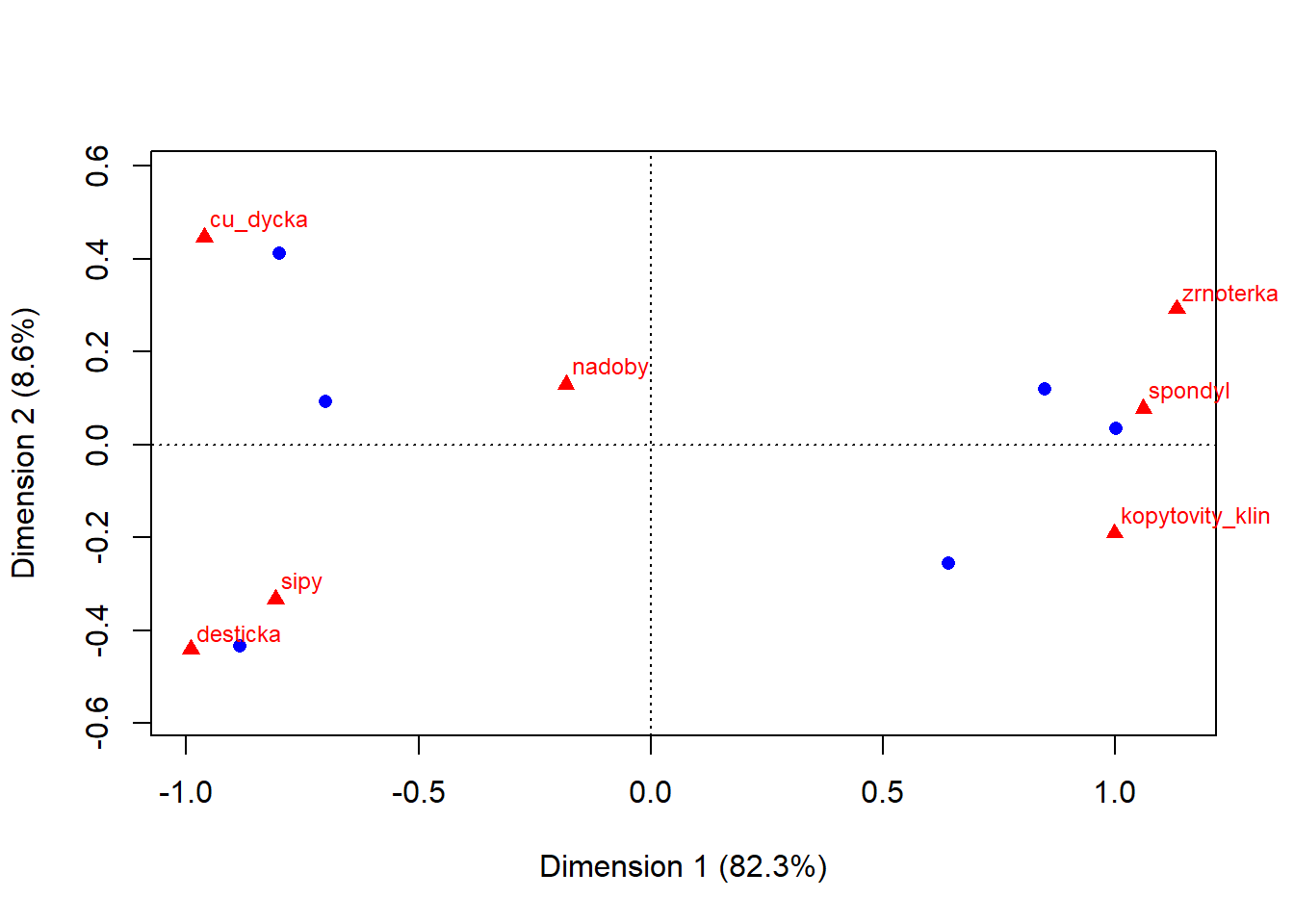
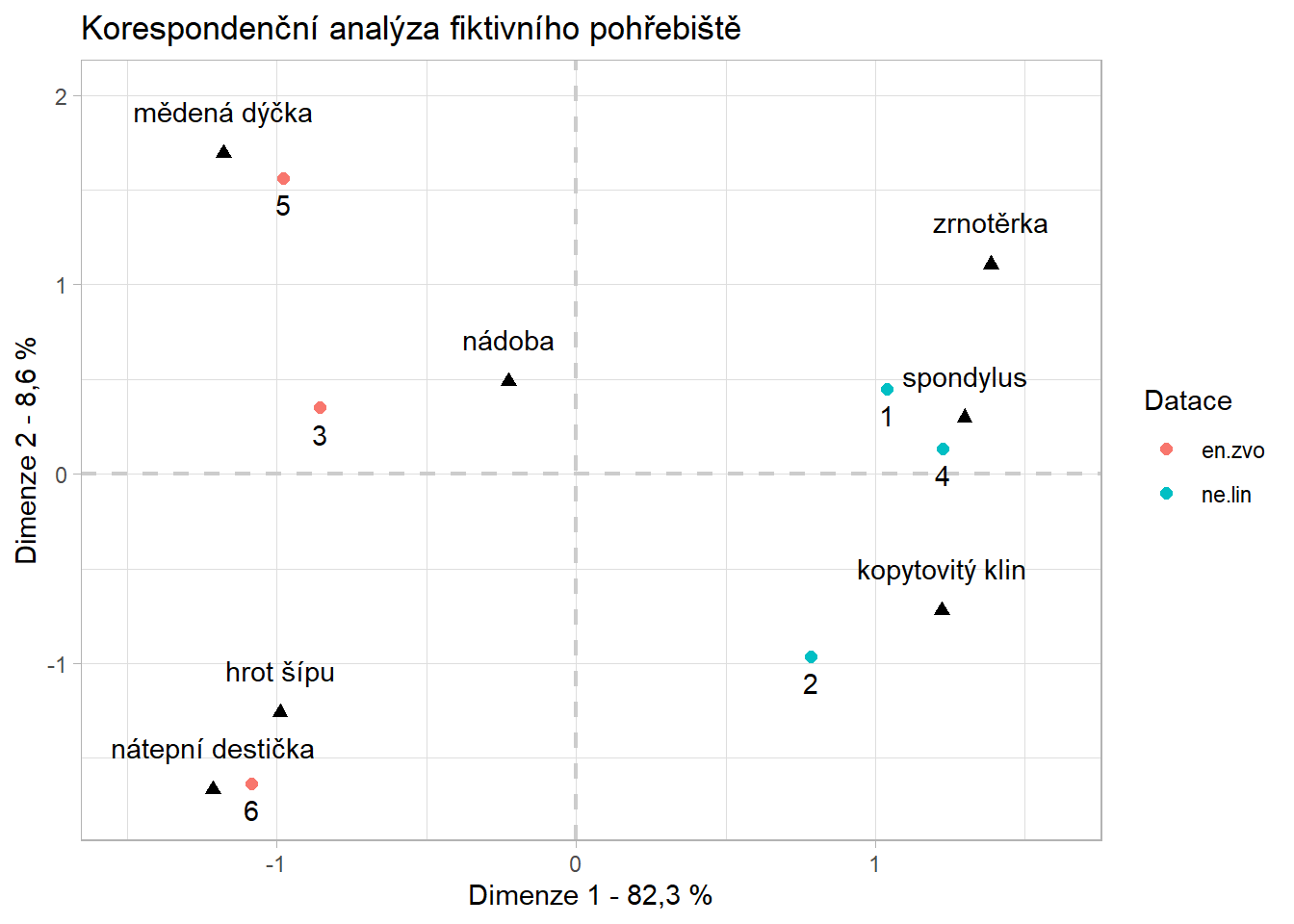
- there are two clearly distinct groups of graves with distinct types of artefacts
- on the other hand number of vessels seems to be indifferent to the groups - both grave groups share similar number of ceramic vessels
- the x axis explains 82 % of the difference between graves and artefacts, y axis only 9 %. This mean that the difference between those two groups is bigger then within them. In other words, the difference between e.g. copper dagger (cu_dycka) and spondylus is much much greater then between the copper dagger and arrow heads (sipy)
Visualising CA in ggplot
- in order to visualize data in ggplot, they have to be in dataframe format
- so the first step will be extracting coordinates from the CA result
- in this case we will extract them from first two dimensions only
x1 and x2 represent coordinates of row values (graves), y1 and y2 represent column values (artefacts)
quick check:
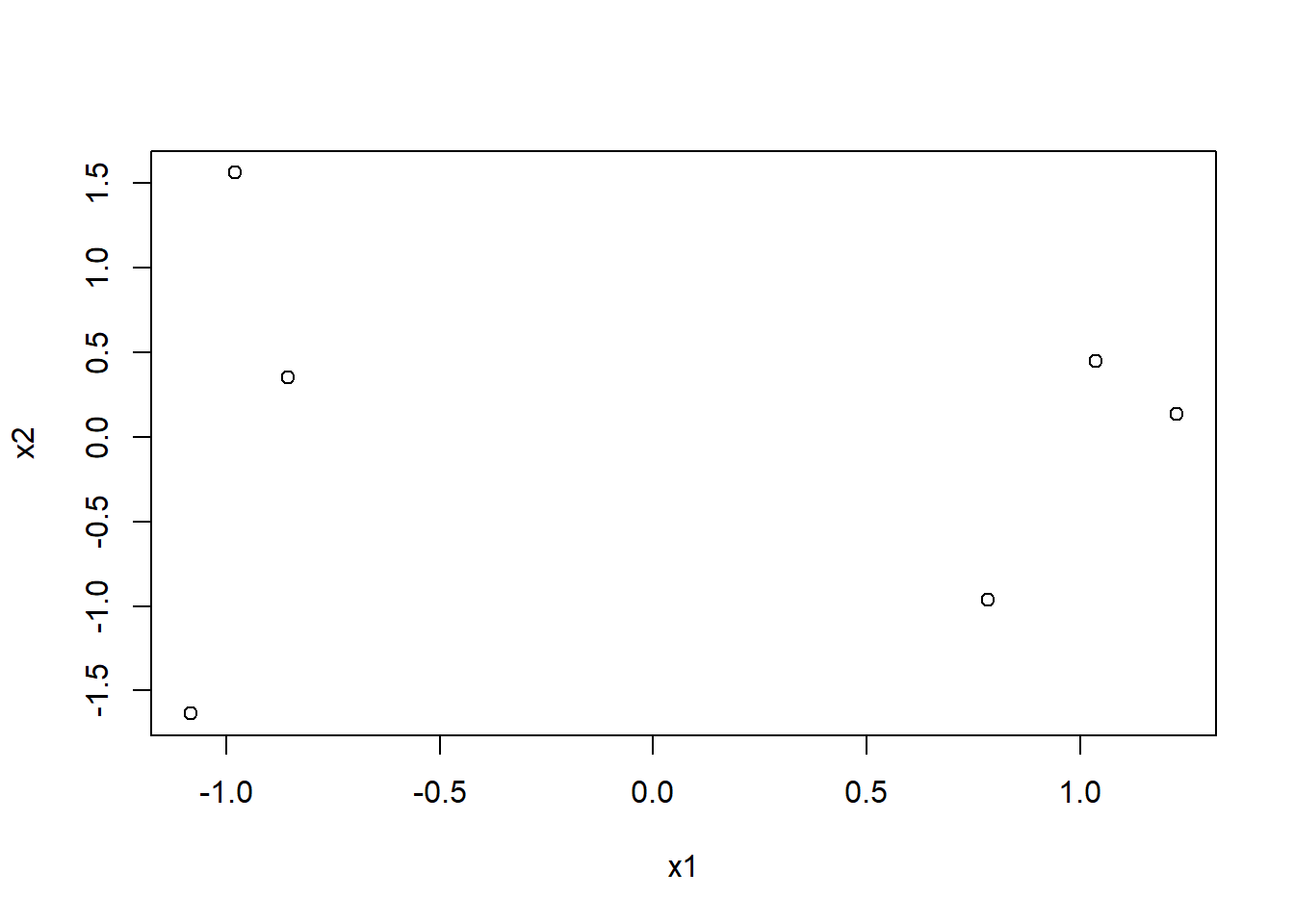
A very simple ggplot
- lets have a quick ggplot
- notice there are 2 types of values in 2 dataframes, so you need to call
geom_point()two times - in ggplot we can also easily distinguish different datations by color
Advanced ggplot
- now you can play more with adjusting the plot
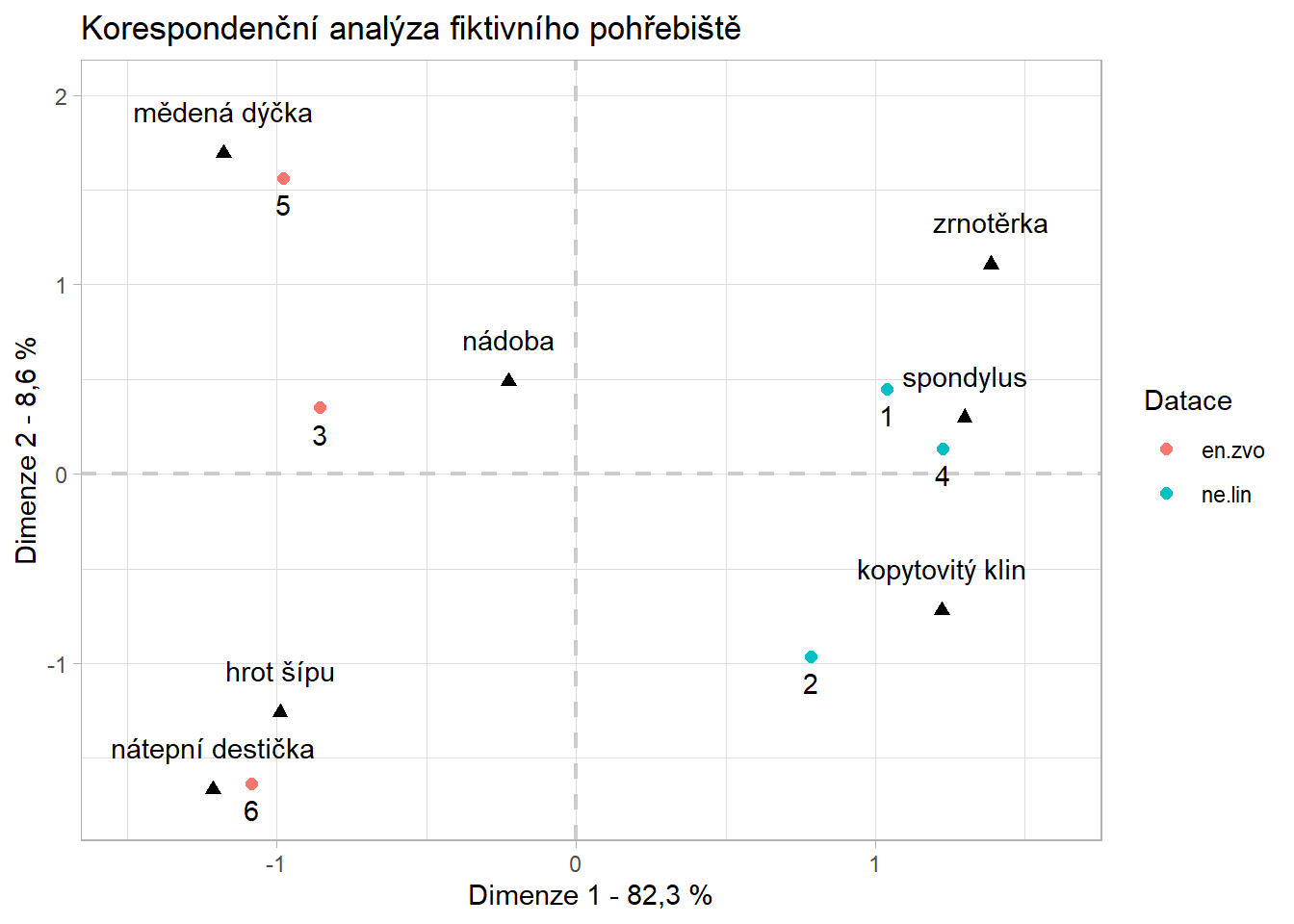
Solution
- you can add text to your ggplot by
geom_text() - you can also rename plot labels without the need to rename variables in your original dataframe. To do so, create a vector with label names and then specify it in
geom_text(...,aes(label=your_vector)) - for more tips how to adjust text see ggplot2.tidyverse.org
ggplot()+
geom_vline(xintercept = 0, color="gray80", linewidth = 0.75, linetype = "dashed")+
geom_hline(yintercept = 0, color="gray80", linewidth = 0.75, linetype = "dashed")+
geom_point(data = coord_datace, aes(X1, X2, colour = Datace), size = 2)+
geom_point(data = coord_artefakty, aes(Y1, Y2), shape = 17, size = 2)+
geom_text(data = coord_artefakty, aes(label = labels_artefacts, x=Y1, y=Y2), vjust = -1.5)+
geom_text(data = coord_datace, aes(label = ID, x=X1, y=X2), vjust = 1.75)+
xlim(-1.5, 1.6)+
ylim(-1.75, 2)+
labs(x="Dimenze 1 - 82,3 %", y="Dimenze 2 - 8,6 %",
title = "Korespondenční analýza fiktivního pohřebiště")+
theme_light()